ArchitectureNr 3 Wiesz jak już w Dockerze robi obraz do różnych frameworków i do różnych języków programowania. Jeśli nie to zawsze możesz przeczytać poprzedni wpis.
Docker potrafi zarządzać obrazami i kontenerami, ale dla zaawansowanych aplikacji i dla prawdziwych firm może to być za mało.
Dlatego powstał Kubernetes?
Coraz więcej rzeczy idzie do chmury. W chmurze możesz utworzyć serwer zainstalować na nim system operacyjny jak Windows czy Linux i przy pomocy niego zarządzać zasobami każdej aplikacji
W chmurze Amazon,Azure, Google także możesz zainstalować Kubernetes, który zrobi to wszystko 1000 razy lepiej.
Kubernetes więc potrafi zarządzać obrazami i kontenerami aplikacji. Od razu możesz zadać sobie pewne pytania.
Jeśli te aplikacje w kontenerach są mikroserwisami to, jak one mają do siebie gadać między sobą.
Co, jeśli jednak aby te aplikacje były zamknięte w sobie i nieotwarte na świat. Co, jeśli jedna z moich aplikacji w kontenerze się wywali? Co, jeśli jednak z moich aplikacji w kontenerze zajmuje za dużo pamięci RAM? Co, jeśli chce mieć przygotowaną konfigurację dla moim aplikacji?
Te problemy potrafi rozwiązać Kubernetes. Jakie są jego zalety?
Pamiętam jak jednej z rozmów kwalifikacyjnych mnie spytali : "Jakby pan zrobił Zero Downtime Deployment?".
Jak wdrożyć aplikację bez wyrywania użytkownika z korzystania z twojej aplikacji. Jak myślisz, dlaczego wiele firm robi wdrożenia miedzy 0:00, a 4:00 rano.
Tak zwane nocki niedługo jednak będą mogły odejść zapomnienie, ponieważ korzystając z kontenerów i Kubernetes możesz wdrożyć aplikację różnymi zwariowanymi strategiami i co najważniejsze użytkownik tego nie zauważy. Możesz zrobić wdrożenie z samego rana i będzie w porządku.
W zależności od strategi twojego wdrożenia możesz albo podmieniać stopniowo stare obrazy aplikacji na nowe, albo podmienić je wszystkie od razu.
Nazywamy to "Zero Downtime Deployments" ?
Kubernetes potrafi naprawiać swoje podpięte obrazy. Co, jeśli twoja aplikacja jest chora albo przestała działać. Kubernetes za Ciebie wywali tą instancje aplikacji i stworzy nową. To jest mechanizm samoleczenia, do którego wrócimy jeszcze nie raz.
Aplikacje łatwo także się skaluje. Zmieniasz jedną opcję i nagle możesz stwierdzić, że potrzebujesz 10 kopii swojej aplikacji bądź serwisu. W każdej chwili też możesz stwierdzić, że już tego nie potrzebujesz i ograniczyć instancje aplikacji do 1.
Architektura Kubernetes
Zanim zaczniemy tworzyć pody, kontenery w wierszu poleceń warto omówić podstawy Architektury Kubernetes.
Kluster Kubernetes posiada kilka MasterNode. MasterNode kontroluje wszystko i do niego bezpośrednio wysyłasz polecenia potem w Wierszu Poleceń albo przez API.
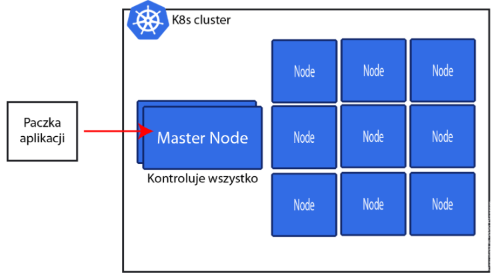
Jeżeli chodzi o pracę związaną z twoim kontenerami to od tego są Node. Może być ich bardzo wiele. Jeżeli chodzi wersje Kubernetesa do testów, którą możesz instalować z Dockerem to możesz potem sprawdzić, że masz tak naprawdę jeden Node do pracy.
Jeśli chodzi o poważne zastosowanie w chmurze i na produkcji to tych Node będziesz miał dużo.
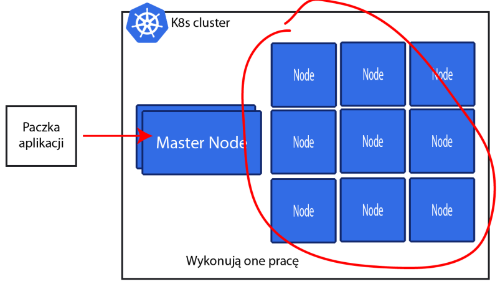
Do klustera Kubernetes wysłały jakąś paczkę, która opisuje jak nasza aplikacja ma wylądować jako kontener.
Czym jest jednak ta paczka? Czy to jakaś definicja obrazu, czy kontenera aplikacji ?
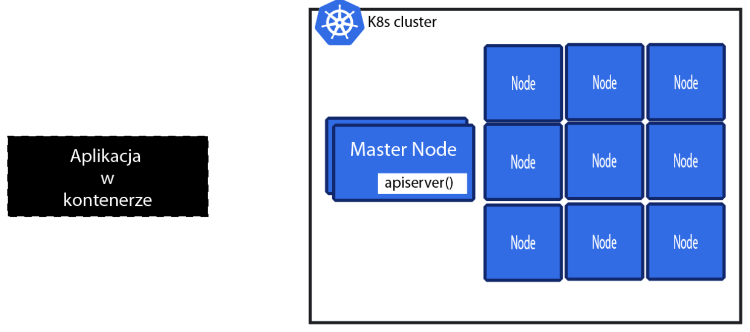
Ten obrazek jest błędny, ponieważ Kubernetes nie pracuje na gołych kontenerach. Umieszcza je natomiast w Pod-ach.
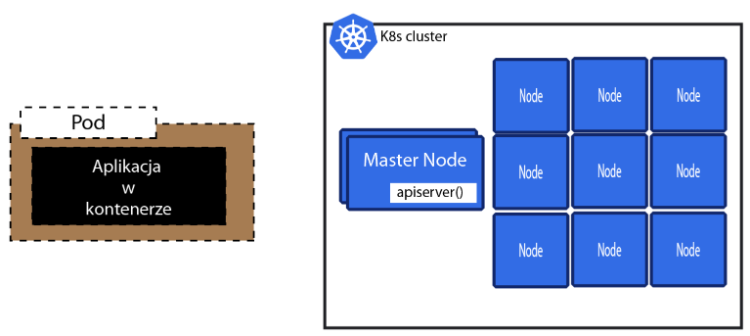
Tylko jeśli chcemy aby nasza aplikacja się skalowała oraz samoleczyła to musimy to opakować w "deployment".
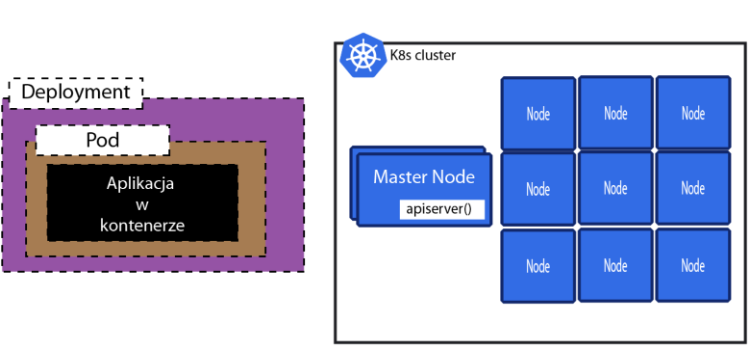
Mamy więc takie coś. Deployment, który zawiera jeden Pod a Pod zawiera jeden kontener.
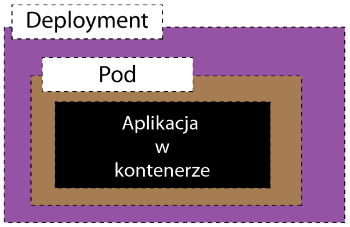
Teraz gdzie my to wszytko definiujemy?
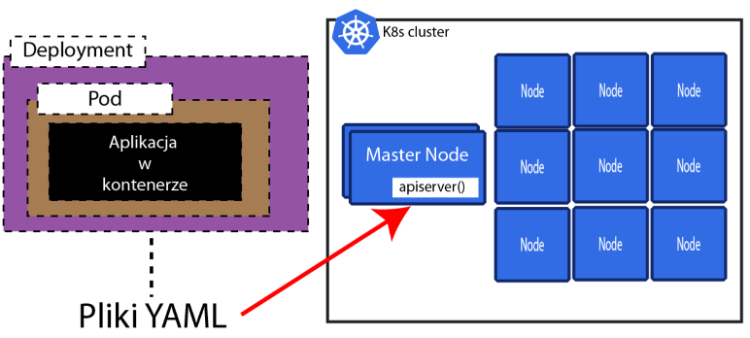
Robimy to w plikach YAML. Mając te pliki YAML wpisujemy potem odpowiednie komendy do wiersza poleceń i to wszystko potem trafia do Master Node.
Wejdźmy głębiej. Dlaczego warto mieć więcej "Master Node"? Jeśli już trzeba mieć ich więcej to ile dokładnie.
Gdyby z jakiegoś powodu stracił dostęp do MasterNoda to byłbyś w niezłym problemie prawie nie do rozwiązania. Poza tym, jak wszystko zawsze coś może się popsuć.
Tak czy siak, ciężko jest kierować samochodem, gdy nie masz już kierownicy. Dlatego warto mieć kilka Master Nod-ów.
Warto to, żeby ich instancja była liczbą nie parzystą, abyś mógł uniknąć problemu head-split, który potrafi stworzyć deadlock między instalacjami Master Node.
Takie problemy wynikają z tego, że zawsze jeden z Master Node jest przywódcą i on dyktuje co inne master nody powinny robić. Co jednak się stanie, gdy dwa Master Node dostaną sprzeczne polecenia i wezmą do siebie taką samą liczbę śledzących Master Nod-ów.
No właśnie.
Oczywiście ich liczba powinna być ograniczona.
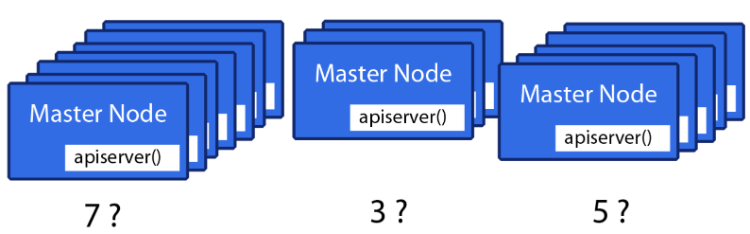
Trzy i pięć wystarczy. Siedem to już za dużo.
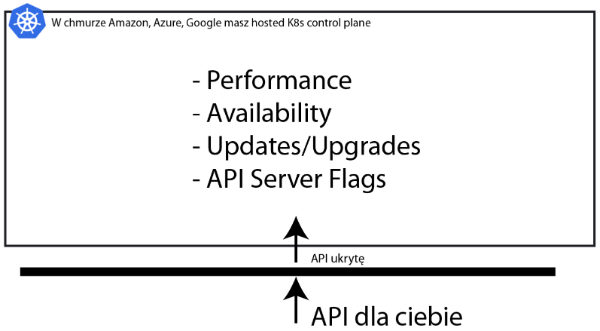
Większość tych problemów może Cię nie dotyczyć. Chmura Amazon, Google oraz Azure ukrywa wiele zaawansowanych opcji przed tobą.
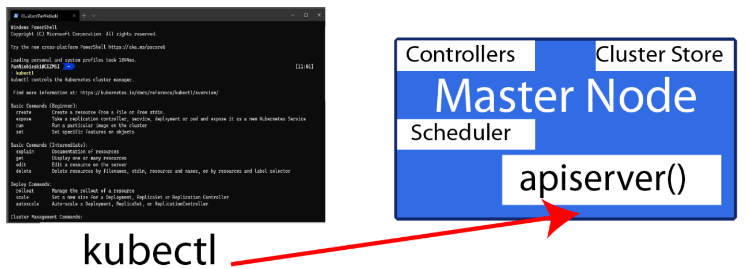
Z czego składa się Master Node
Oto z czego składa się każdy Master Node
kube-apiserver zawiera
- REST API
- Potrafi on pobierać JSON/YAML
- Front-end-owy panel sterowania
Cluster Store
- Zawiera on ustawienia stanu, czyli co i jak jest ustawione
- Bazuje na bazie NoSQL
- Jest on krytyczny dla wydajności.
Kube-controller
- Kontroler do kontrolerów
- On robi pętlę watch, czyli obserwuje
- Dba on o spójność pomiędzy desired state, a observed state
Kube-scheduler
- Obserwuje on API dla nowych zadań
- Nadaje on zadania dla innych nodów
Ostatecznie to ty w wierszu poleceń wpiszesz odpowiednio komendę lub podasz plik YAML aby uruchomić te wszystkie mechanizmy w Master Node.
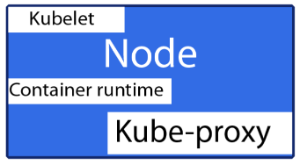
Z czego składa się sam Node
Kubelet
- Główny agend Kubernetes
- Rejestruje node w cluster Kubernetes
- Obserwuje on Pod-y
Container runtime
- Na razie może to być Docker
- W przyszłości może to być dowolny silnik, który spełnia Container Runtime Interface
- Pamiętasz jak w pierwszym wpisie z tego cyklu omówiliśmy, że w przyszłości trzeba będzie wybrać innym program do zarządzania kontenerami oto gdzie to się odbywa w architekturze Kubernetes.
Kub-proxy
- Sieciowy mechanizm
- Daje on pod-om adresy IP i nie tylko
Teraz gdy omówiliśmy architekturę Kubernetes warto wyjaśnić kolejną rzecz.
Deklaratywny styl i stan obserwowany
Deklaratywny model polega na tym, że opisujesz w pliku YAML jak stan jest przez Ciebie pożądany.
Na razie nie będziemy patrzeć na całą definicję pliku YAML. Na razie wystarczy Ci wiedzieć, że w tym pliku określiłem wartość : replicas na 3.
Czy moja aplikacja powinna się pojawić jako Trzy Nody, a każdy z nich będzie zawierał swój Pod?
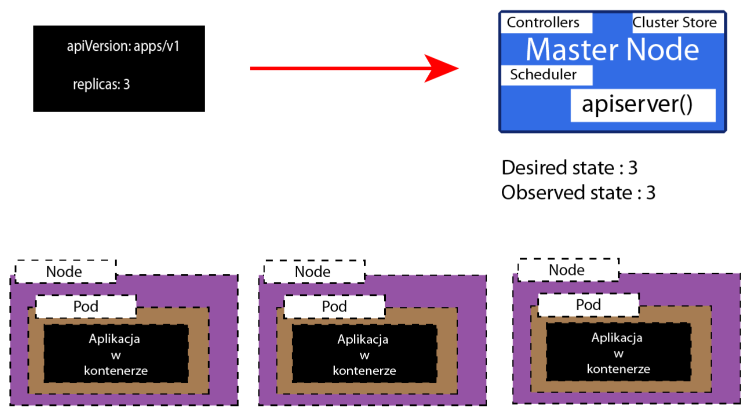
Kubernetes zrobił swoje zadanie i na razie stan określony przez ze mnie w pliku jest taki sam jak stan aplikacji utworzonych przez Kuberentes
Czyli stan Obserwowany równa się stanu Desired.
Co się jednak stanie, gdy jeden z tych Nodów czy Pod-ów się wywali i przestanie działać.
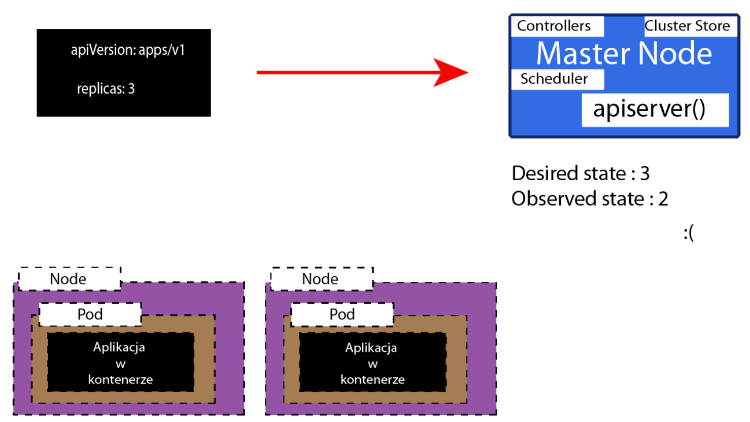
Kubernetes wtedy zauważy, że stan obserwowany nie równa się już stanowi porządanemu
Zrobi on wszystko aby ten stany były znowu sobie równe,
Utworzy więc on nową instancje naszej aplikacji, aby znowu były 3 repliki.
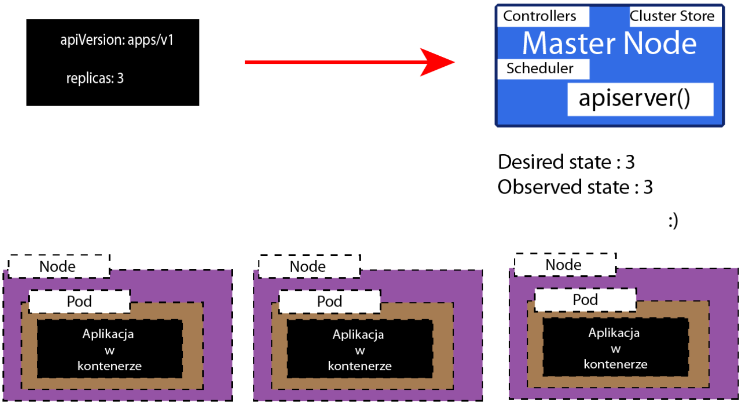
Tak w dużym skrócie działa mechanizm samoleczenia.
Pody
Czy w pod-ach można mieć więcej kontenerów?
Tak, tylko po co
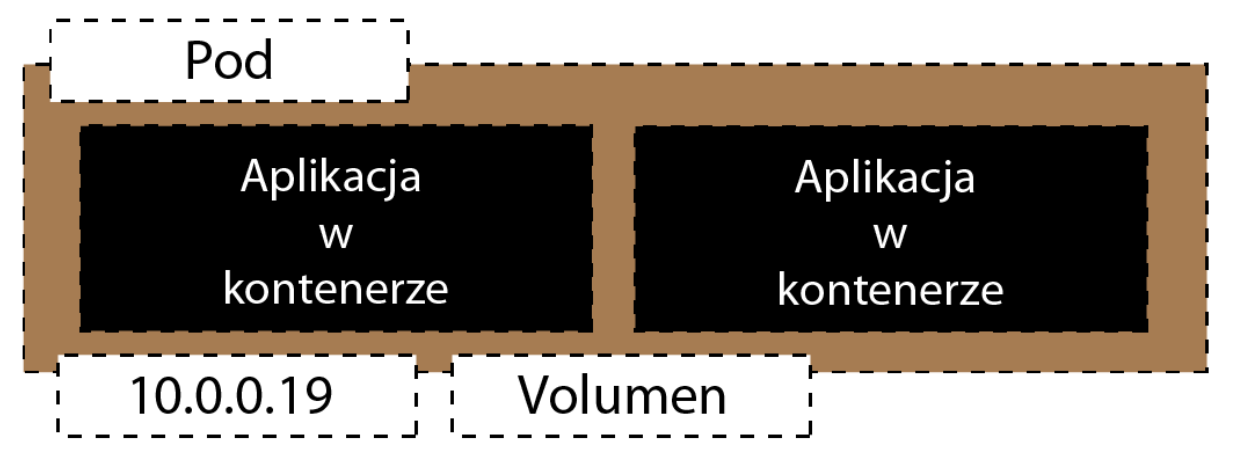
Każdy kontener wtedy współdzielą między sobą jeden adres IP oraz zasoby plikowe, jeśli takie zdefiniowaliśmy w pliku YAML.
Mówimy na to Volumen
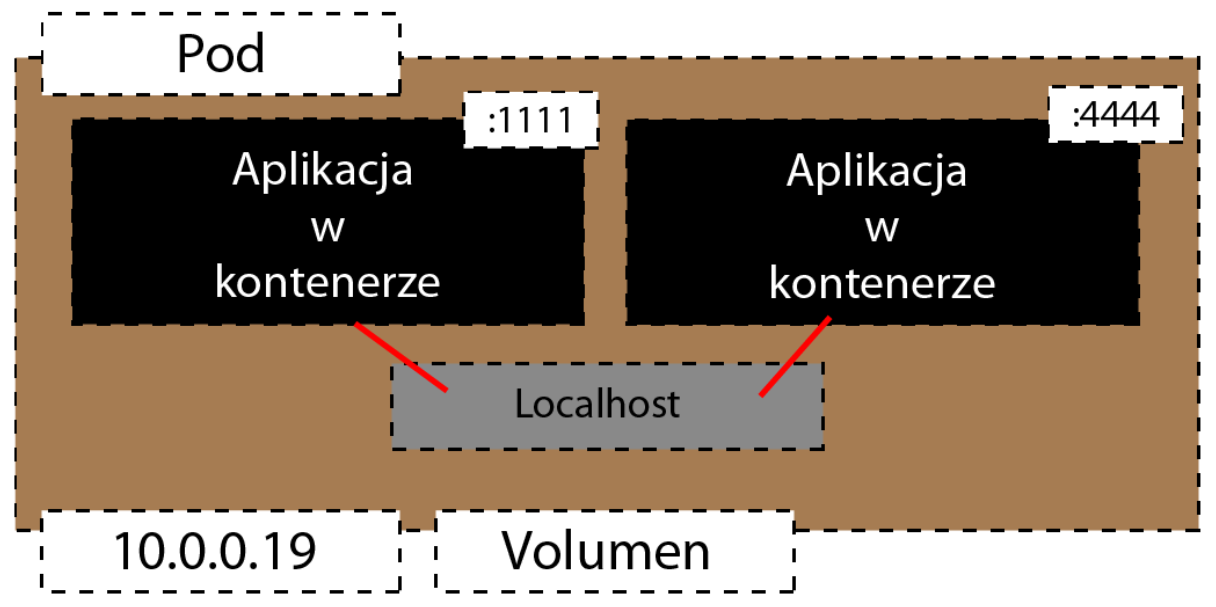
Dodatkowo te aplikacje mogą między sobą gadać korzystając z localhost.
Dlaczego jednak tak nie robić?
Ciężko taką aplikację skaluje się w chmurze i komplikuje to bardziej architekturze.
Skalujesz pody, a każdy pod potem ma te dwa kontenery i ciężko potem sobie wyobraź jak to działa. Musisz traktować dwa kontenery w jednym pod-zie jak były jedną instancją jakiegoś mechanizmu.
Bądźmy szczerzy nie zawsze tak będzie.
Pody i Sieć
Teraz pora przejść do najbardziej skomplikowanej części Kubernetes według mnie.
Możesz np. opakować definicje Pod-a w Deployment to pozwoli mieć ci kilka instancji twojej aplikacji
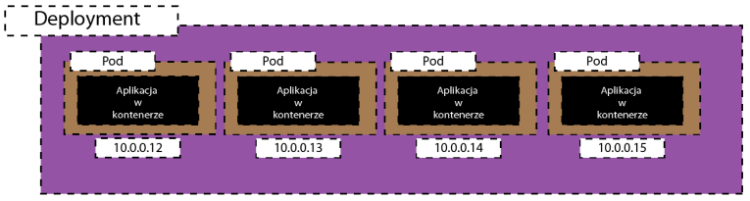
Każda instancja Pod-a będzie miała swój adres IP.
Teraz jak komunikować się z Pod-ami? Robimy to tak ?
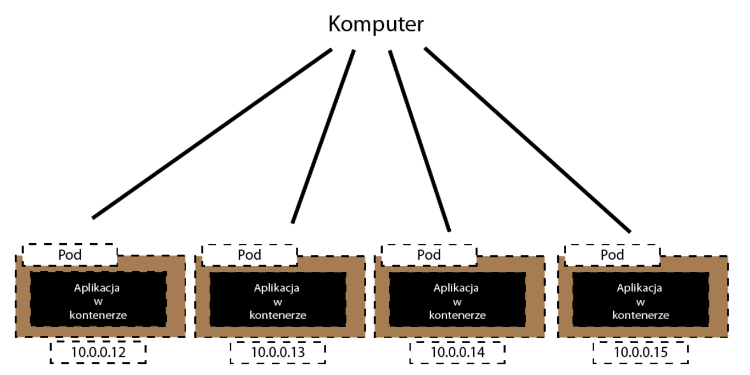
Oczywiście, że nie
Każdy Pod będzie usuwany, jeśli coś pójdzie nie tak. Z każdym taką operacją powstanie nowy Pod a nowy Pod to nowy adres IP. Oznacza to, że te adresy IP w ogóle nam do niczego nie są potrzebne, a na pewno nie powinnyśmy z nich korzystać.
Oto moja lista pod-ów i jak widzisz każdy z nich restartował się przynajmniej dwa razy.
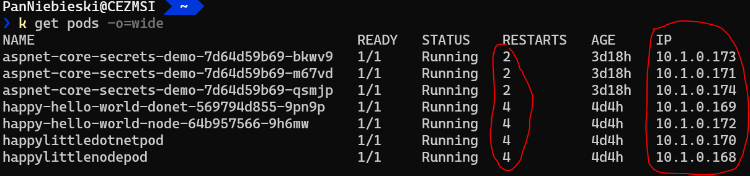
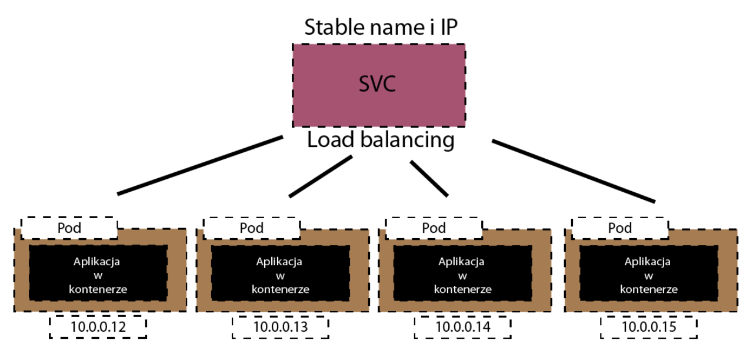
Dlatego będziemy potrzebować jakiego serwisu, który byłby taką bramą do tych wszystkich instancji pod-ów.
On będzie miał stabilny adres IP i nawet on może mieć mechanizm zarządzania ruchem sieciowym wykonanym po naszej aplikacji.
Teraz gdy nagle dwa pody będą musiały zniknąć albo to z powodu błędu, albo to z powodu twojej ingerencji, bo może wygrywasz nowy obraz do nich - to w sumie nic się nie stanie.
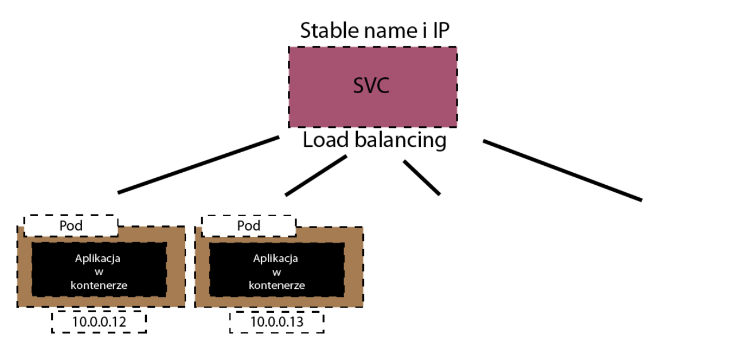
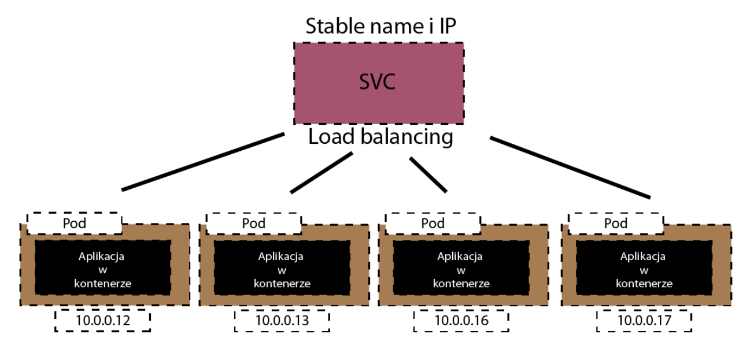
Kubernetes będzie pilnował swojego stanu pożądanego i na nich miejsce utworzy nowe pody z innymi adresami IP.
Dla nas to jednak bez znaczenia, ponieważ mamy usługę, która nas chroni przed niestabilnymi zachowaniami Pod-ów.
To było wszystko, jeśli chodzi o wiedzę teoretyczną Kubernetes.
Nadszedł czas coś zbudować korzystająca z wiersza poleceń i plików YAML.
;


