InterpreterWzór.24 Celem wzorca "Interpreter" jest zinterpretować dane wyjściowe zazwyczaj w formacie tekstowym, tak abyśmy mogli wykonać specyficzne akcje. Jednakże dane wyjściowymi nie muszą być koniecznie w formacie tekstowym.
"Interpreter" jest powiązany z kompilatorem. Warto zaznaczyć, że oba pojęcia nie mówią dokładnie o tym samym, chociaż można ich używać zamiennie. Przypadku języków programowania różnice są takie:
- Kompilator : kompiluje język programowania do jakiegoś kodu maszynowego. Tak działają języki bazujące na C i C++ jak Java czy C#. W kompilatorze więc zawiera się Interpreter, bo w końcu coś musi zrozumieć składnie kodu, aby go przetransformować.
- Interpreter : nie przekształca kodu, tylko go uruchamia interpretując go. Tak działa Perl,Python, Matlab
Być może na studiach zostałeś zmuszony napisać prymitywny kompilator, aby zaliczyć przedmiot. Tak pisanie kodu w innym języku programowania, aby potem dostać kod maszynowy w wyniku kompilacji, jest też formą wzorca "Interpreter".
"Interpreter" też może się ukrywać pod inną nazwą jak:
- "Parsers" tłumaczonych potocznie na polski parsery.
- oraz Analizatory składniowe
Jakie przykładowe parsery mamy w .NET i ogólnie w programowaniu:
Wyrażenia regularne (Regular expressions) : Co robimy, aby znaleźć specyficzne fragmenty tekstu ze skomplikowanymi zasadami.Przykładowo jakbyś napisał kod, który by wyszukał wszystkie wystąpienia adresów e-mail w tekście. Na pomoc przychodzą wyrażenia regularne, które mają swoja składnie i specyficzne zasady. Każde wyrażenie jak na przykład te...
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9]))\.){3}(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9])|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])...potrzebuje swojego interpretera.
Struktury danych jak CSV, XML, JSON, YAML, pliki Excel wymagają odpowiedniego interpretera, aby mogły być odczytane i użyte.
Wyrażenia drzewiaste są kompilowane na wyrażenia lambda, czyli mają swojego interpretera.
Każdy język programowania ma swój kompilator, który interpretuje kod i go transmituje na coś innego. Przykładowo TypeScript może być przetransformowany na język JavaScript poprzez interpretacje.
Na potrzeby tego wpisu. Stwórzmy więc swój własny interpretator. Będziemy analizować tekst i zamieniać go na tokeny. Ta część programu nazywa się "Lexer".
Później te tokeny zamienimy na poszczególne wartości, czyli będziemy "Parsować".
Co budujemy?
Naszym celem jest napisać program, który przetłumaczy tekst pisany w stylu "/u/l/{tekst" na wyrażenie HTML.
Oto dwa przykłady tego, jak ma mój program ma działać.
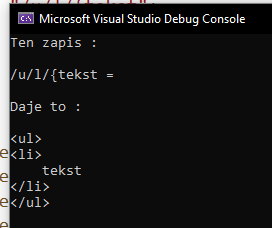
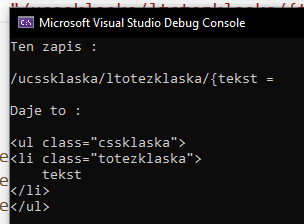
Przykład nie jest idealny, ale jeśli będziesz budował swój interpreter oto cegiełki do niego.
Lexing
Pierwsza operacja, która nas interesuje będzie polegać na zmianie polecenia tekstowego na zbiór tokenów.
Z czego powinien składać się nasz token. Powinien mieć informację o swoim typie oraz o przetrzymywanej wartości, która będzie oznacza różne rzeczy w zależności od kontekstu czy swojego typu.
public class Token
{
public enum Type
{
Ul, Li, Text,
}
public Type MyType;
public string Text;
public Token(Type type, string text)
{
MyType = type;
Text = text;
}
public override string ToString()
{
return $"`{Text}`";
}
}Teraz musimy mieć metodę, która przetłumaczy te wyrażenie tekstowe na zbiór tokenów
IReadOnlyList<Token> Lex(string input)
{
string[] words = input.Split("/");
var result = new List<Token>();
foreach (var word in words)
{
string text = "";
if (word.Length > 1)
text = word.Substring(1);
if (word.Length == 0)
continue;
Token t;
if (word[0] == 'u')
t = new(Token.Type.Ul, text);
else if(word[0] == 'l')
t = new(Token.Type.Li, text);
else if(word[0] == '{')
t = new(Token.Type.Text, text);
else
t = new(Token.Type.Text, "");
result.Add(t);
}
return result;
}
Logika jest następująca. Jeśli pierwszy znak to 'u' to wtedy uznaje, że chce wstawić element html <ul> gdzie dalszy tekst jest określeniem jego klasy CSS.
Analogicznie postępuje dla znaku 'l', który określa mi, że chce wstawić element html <li>.
Natomiast nawias klamrowy '{' mówi, że teraz mam wstawić token tekstowy. Mógłbym umieścić więcej typów tokenów, ale my chcemy prosty przykład, który pomoże ci w przyszłości napisać podobny kod.
Parsowanie
Parsowanie będzie polegało na transformacji uniwersalnych tokenów na dokładniejsze klasy, które określą nam potem ostateczny wynik tekstowy danego wyrażenia.
Pisząc taki interfejs łamię zasadę "Interface Segregation Principle".
Nie każda właściwość będzie używana przez klasy implementujące ten interfejs , ale tak jak mówiłem ten przykład nie jest idealny.
public interface IElement
{
string Value { get; }
string AfterValue { get; }
public IElement Child { get; set; }
}Teraz stwórzmy klasy, które będą określać zachowanie moich poszczególnych elementów wyrażenia.
Tak wygląda element tekstowy:
public class TextElement : IElement
{
public TextElement(string value)
{
Value = " "+ value;
}
public string Value { get; }
public IElement Child { get; set; }
public string AfterValue => "";
}Tak będzie wyglądać element <li> i <ul>.
public class UlElement : IElement
{
public UlElement(string cssclass)
{
if (!string.IsNullOrWhiteSpace(cssclass))
Value = $"<ul class=\"{cssclass}\">";
else
Value = $"<ul>";
AfterValue = "</ul>";
}
public string Value { get; }
public IElement Child { get; set; }
public string AfterValue { get; }
}
public class LiElement : IElement
{
public LiElement(string cssclass)
{
if (!string.IsNullOrWhiteSpace(cssclass))
Value = $"<li class=\"{cssclass}\">";
else
Value = $"<li>";
AfterValue = "</li>";
}
public string Value { get; }
public IElement Child { get; set; }
public string AfterValue { get; }
}Potrzebuje też klasy rodzica, który będzie mi przetrzymywać te wszystkie elementy, a potem całe te wyrażenia przetworzy na ostateczny tekst.
Ponieważ mamy element w elemencie to nie obędzie się bez rekurencji.
public class HtmlOperation : IElement
{
public IElement Child { get; set; }
public string Value
{
get
{
StringBuilder sb = new StringBuilder();
sb = Rec(sb,Child);
return sb.ToString();
}
}
public string AfterValue => "";
private StringBuilder Rec(StringBuilder sb, IElement e)
{
sb.AppendLine(e.Value);
if (e.Child != null)
Rec(sb, e.Child);
if (e.AfterValue != null && e.AfterValue != "")
sb.AppendLine(e.AfterValue);
return sb;
}
}Teraz gdy mamy wszystkie elementy układanki to pozostało nam to napisać metodę, która zamieni te tokeny na nasze konkretne cegiełki HTML.
static HtmlOperation Parse(IReadOnlyList<Token> tokens)
{
HtmlOperation root = new HtmlOperation();
bool haveLHS = false;
for (int i = 0; i < tokens.Count; i++)
{
var token = tokens[i];
// look at the type of token
switch (token.MyType)
{
case Token.Type.Text:
Insert(root,new TextElement(token.Text));
break;
case Token.Type.Ul:
Insert(root, new UlElement(token.Text));
break;
case Token.Type.Li:
Insert(root, new LiElement(token.Text));
break;
}
}
return root;
}Do tworzenia mojej struktury znowu będzie potrzebna rekurencja.
static IElement Insert(IElement root, IElement nextchild)
{
if (root.Child != null)
return Insert(root.Child, nextchild);
else
{
root.Child = nextchild;
return root;
}
}Program ten nie jest idealny. Po pierwsze nie łapie wszystkim możliwych nieprawidłowych wartości. Czy ten przykład można rozwijać? Oczywiście, że tak można do niego dodać kolejne tagi HTML i inne skrótowe oznaczenia, które wydrukują się specyficznie w tekście końcowym.
Użycie naszego Parsera i Lexera.
Oto użycie naszego Parsera i Lexera. Program działać jak na obrazkach powyżej.
var input = "/ucssklaska/ltotezklaska/{tekst";
var tokens = Lex(input);
var parsed = Parse(tokens);
Console.WriteLine($"Ten zapis :\n");
Console.WriteLine($"{input} = \n");
Console.WriteLine($"Daje to :\n");
Console.WriteLine($"{parsed.Value}");Podsumowanie
Wzorzec projektowy "Interpreter" jest bardzo rzadki. Pisanie swoich parserów zazwyczaj dotyczy jakiś błahych przykładów więc nie trzeba pisać tylu klas, aby wykonać swoje zadanie.
Nawet ten prosty przykład wzorca można było napisać po prostu dużą grupą warunków if i else. Chociaż z drugiej strony, jeśli planuje swojego Interpretera rozwijać to rozbicie tego kodu na tokeny i elementy do parsowania ma moim zdaniem sens.
Jeśli interesuje Cię tematyka pisania własnych kompilatorów to trochę źle trafiłeś. Mogę Cię odesłać do frameworków jak "Lex/Yacc" i "ANTLR".
Swoją przygodę też możesz zacząć od pisania pluginów do analizy kodu w samym Visual Studio.
Kompilator Roslyn to też temat rzeka, który nawet mnie kiedyś wciągnął do generowania dynamicznego całych projektów z kodem w Visual Studio.


