RememberCzęść NR.13 W poprzednim wpisie omówiliśmy techniki z programowania funkcyjnego jak Precomputation i Memoization. Pytanie, jak te techniki mają się do kodu w C#, który jest asynchroniczny i opiera się na obiektach takich jak Task, które symbolizują w C# przyszłość.
Jak się domyślasz Memoizacja może być bardzo utrudniona. W poprzednim wpisie nawet zaznaczyłem, że same słowniki Dictionary nie są wielowątkowo bezpieczne.
Trzeba by było korzystać z innych słowników, które są bardziej bezpieczne jak ConcurrentDictionary
A co z Precomputation? Nie wiem czy wiesz, ale sam obiekt klasy Task wspiera tą filozofię aby nie wyliczać ponownie czegoś co już zostało zrobione.
Przykładowo, jeśli spróbujesz zrobić await na danym Task-u kilka razy to maszyna stanów async i await wykona zadanie tylko raz, a potem będzie zwracać przechowany ten sam wynik.
Task<string> t =
File.ReadAllTextAsync(@"D:\numbers2.txt");
await t;
await t;
await t;
await t;Ten mechanizm działa, gdyż operujesz na tej samej referencji zadania, które już się zakończyło przy pierwszy wywołaniu. Niestety nie zawsze będziesz miał taki luksus, aby z tego mechanizmu skorzystać, a to znaczy, że trzeba go napisać po swojemu.
Własne Precomputation z Task.WhenAll. Czy potrzebne ?
A co jeśli masz grupę zadań. Czy ten mechanizm w takim wypadku działa tak samo? Sprawdźmy to.
Spójrz na ten kod napisany według nowego stylu Top Level Class z C# 9.0. Pozwala on napisać kod aplikacji konsolowej bez opakowania go w klasę. W C#10.0 taki kod będzie robił jeszcze większy efekt woo.
Chcemy pobrać asynchronicznie zawartość różnych stron z różnych adresów HTTP. Możemy te operację asynchroniczne potem razem skupić poprzez użycie Task.WhenAll i powiedzieć, że gdy wszystkie te zadania się skończą wtedy chcemy wyświetlić łączną liczbę pobranych znaków stron HTML.
using System;
using System.Collections.Concurrent;
using System.Collections.Generic;
using System.Diagnostics;
using System.Linq;
using System.Net.Http;
using System.Threading.Tasks;
ConcurrentDictionary<string, string> s_cachedDownloads = new();
HttpClient s_httpClient = new();
string[] urls = new[]
{
"https://twitter.com/WalenciukC",
"https://www.facebook.com/cezary.walenciuk",
"https://www.instagram.com/cezarywalenciuk/",
"https://github.com/PanNiebieski",
"https://www.youtube.com/channel/UCaryk7_lKRI1EldZ6saVjBQ",
"https://www.facebook.com/JakProgramowac?fref=nf"
};
IEnumerable<Task<string>> downloads = urls.Select(DownloadStringAsync2);
IEnumerable<Task<string>> downloads2 = urls.Select(DownloadStringAsync2);
IEnumerable<Task<string>> downloads3 = urls.Select(DownloadStringAsync2);
Stopwatch stopwatch = Stopwatch.StartNew();
var f = await Task.WhenAll(downloads);
StopAndLogElapsedTime2(1, stopwatch, f);
stopwatch.Restart();
var f2 = await Task.WhenAll(downloads2);
StopAndLogElapsedTime2(2, stopwatch, f2);
stopwatch.Restart();
var f3 = await Task.WhenAll(downloads3);
StopAndLogElapsedTime2(3, stopwatch, f3);
void StopAndLogElapsedTime2(
int attemptNumber, Stopwatch stopwatch, string[] downloadTasks)
{
stopwatch.Stop();
int charCount = downloadTasks.Sum(result => result.Length);
long elapsedMs = stopwatch.ElapsedMilliseconds;
Console.WriteLine(
$"Numer próby: {attemptNumber}\n" +
$"Liczba pobranych znaków: {charCount:#,0}\n" +
$"Ile czasu mineło: {elapsedMs:#,0} milliseconds.\n");
}
Task<string> DownloadStringAsync2(string address)
{
return Task.Run(async () =>
{
var content = await s_httpClient.GetStringAsync(address);
return content;
});
}Klasa StopWatch pozwoli nam zmierzyć czas wykonywania kodu. Jeśli będzie on równy zero to znaczy, że operujemy na wartościach zapisanych przez C# w maszynie stanów.
Oto wynik tego kodu. Jak widzisz kolejna próby pobierają nasze strony internetowo ponownie. Czasy są różne ze względu na prędkość mojej sieci i także jak widać jedna lub więcej ze stron wyświetliła się inaczej stąd inna liczba pobranych znaków.
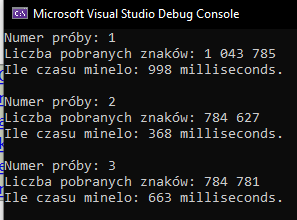
Czyli jak widzisz mechanizm PreComputation z maszyny stanów async i await nie działa, gdyż tworzymy z każdą taką operacją nową instancję klasy Task, mimo iż wykonujemy te same zadania.
W tym wypadku zawsze tworzymy nową instancję klasy Task poprzez użycie Task.WhenAll i Task.Run dla każdego adresu URL.
Gdybyś chciał stworzyć swój mechanizm, który by pilnował tego aby nie wykonywać tych samych operacji asynchronicznych to by wyglądałby on tak. Musimy tutaj skorzystać z słownika ConcurrentDictionary, który będzie pamiętał o zapisanych wcześniej rezultatach i będzie on bezpieczny wielowątkowo.
using System;
using System.Collections.Concurrent;
using System.Collections.Generic;
using System.Diagnostics;
using System.Linq;
using System.Net.Http;
using System.Threading.Tasks;
ConcurrentDictionary<string, string> s_cachedDownloads = new();
HttpClient s_httpClient = new();
string[] urls = new[]
{
"https://twitter.com/WalenciukC",
"https://www.facebook.com/cezary.walenciuk",
"https://www.instagram.com/cezarywalenciuk/",
"https://github.com/PanNiebieski",
"https://www.youtube.com/channel/UCaryk7_lKRI1EldZ6saVjBQ",
"https://www.facebook.com/JakProgramowac?fref=nf"
};
Stopwatch stopwatch = Stopwatch.StartNew();
IEnumerable<Task<string>> downloads = urls.Select(DownloadStringAsync);
await Task.WhenAll(downloads).ContinueWith(
downloadTasks => StopAndLogElapsedTime(1, stopwatch, downloadTasks));
// Druga próba pobrania
// Powinna być krótsza gdyż rezultaty są w NASZYM cache
stopwatch.Restart();
downloads = urls.Select(DownloadStringAsync);
await Task.WhenAll(downloads).ContinueWith(
downloadTasks => StopAndLogElapsedTime(2, stopwatch, downloadTasks));
static void StopAndLogElapsedTime(
int attemptNumber, Stopwatch stopwatch, Task<string[]> downloadTasks)
{
stopwatch.Stop();
int charCount = downloadTasks.Result.Sum(result => result.Length);
long elapsedMs = stopwatch.ElapsedMilliseconds;
Console.WriteLine(
$"Numer próby: {attemptNumber}\n" +
$"Liczba pobranych znaków: {charCount:#,0}\n" +
$"Ile czasu mineło: {elapsedMs:#,0} milliseconds.\n");
}
Task<string> DownloadStringAsync(string address)
{
if (s_cachedDownloads.TryGetValue(address, out string content))
{
return Task.FromResult(content);
}
return Task.Run(async () =>
{
content = await s_httpClient.GetStringAsync(address);
s_cachedDownloads.TryAdd(address, content);
return content;
});
}W momencie pobrania adresu z danej strony sprawdzamy czy daną stronę już pobraliśmy w naszym słowniku. Jeżeli tak nie jest to tworzy nową instancję klasy Task.
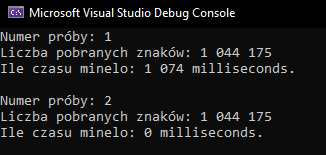
Dzięki temu próba pobrania strony drugi raz trwa 0 milisekund, ponieważ rezultat mamy już zapisany w pamięci.
Ten mechanizm byłby użyteczny, gdybyś za każdym razem pobierał różne strony internetowe i byś w ten sposób unikał pobrania poszczególnych stron dwa razy.
using System;
using System.Collections.Concurrent;
using System.Collections.Generic;
using System.Diagnostics;
using System.Linq;
using System.Net.Http;
using System.Threading.Tasks;
string[] urls = new[]
{
"https://twitter.com/WalenciukC",
"https://www.facebook.com/cezary.walenciuk",
"https://www.instagram.com/cezarywalenciuk/",
};
string[] urls2 = new[]
{
"https://twitter.com/WalenciukC",
"https://www.facebook.com/cezary.walenciuk",
};
string[] urls3 = new[]
{
"https://www.facebook.com/cezary.walenciuk",
"https://www.instagram.com/cezarywalenciuk/",
};
IEnumerable<Task<string>> downloads = urls.Select(DownloadStringAsync);
IEnumerable<Task<string>> downloads2 = urls2.Select(DownloadStringAsync);
IEnumerable<Task<string>> downloads3 = urls3.Select(DownloadStringAsync);
Stopwatch stopwatch = Stopwatch.StartNew();
var f = await Task.WhenAll(downloads);
StopAndLogElapsedTime2(1, stopwatch, f);
stopwatch.Restart();
var f2 = await Task.WhenAll(downloads2);
StopAndLogElapsedTime2(2, stopwatch, f2);
stopwatch.Restart();
var f3 = await Task.WhenAll(downloads3);
StopAndLogElapsedTime2(3, stopwatch, f3);
static void StopAndLogElapsedTime(
int attemptNumber, Stopwatch stopwatch, Task<string[]> downloadTasks)
{
stopwatch.Stop();
int charCount = downloadTasks.Result.Sum(result => result.Length);
long elapsedMs = stopwatch.ElapsedMilliseconds;
Console.WriteLine(
$"Numer próby: {attemptNumber}\n" +
$"Liczba pobranych znaków: {charCount:#,0}\n" +
$"Ile czasu mineło: {elapsedMs:#,0} milliseconds.\n");
}
Task<string> DownloadStringAsync(string address)
{
if (s_cachedDownloads.TryGetValue(address, out string content))
{
return Task.FromResult(content);
}
return Task.Run(async () =>
{
content = await s_httpClient.GetStringAsync(address);
s_cachedDownloads.TryAdd(address, content);
return content;
});
}Pomimo tego, że mamy różne tablicę adresów HTTP to nasz kod nadal korzysta z zapisanych wcześniej rezultatów.
Memoization i async Task
Zobaczmy podobny problem do rozwiązania tym razem przy pomocy wzorca projektowego z programowania funkcyjnego, którego nazywamy Memoization.
Na czym polega różnica pomiędzy PreComputation, a Memoization. Memoization pozwala nam otacza gotowe funkcje, metody w mechanizm zapisu cache tak abyśmy nie musieli tworzyć nowej metody aby ten mechanizm dodać. Omówiłem to szerzej w poprzednim wpisie.
Najpierw zobaczmy jak otoczymy funkcję, gdy mamy kod synchroniczny. Metoda DownloadString jest synchroniczna i wykona się w tym samym wątku. Skoro mamy kod synchroniczny to możemy tutaj skorzystać z Dictionary.
using System;
using System.Collections.Generic;
using System.Net;
var memoizer = Memoize<string, string>(GetWebPage);
var a = memoizer("https://www.cezarywalenciuk.pl").Length;
var b = memoizer("https://www.cezarywalenciuk.pl").Length;
var c = memoizer("https://www.cezarywalenciuk.pl").Length;
string GetWebPage(string uri) => new WebClient().DownloadString(uri);
Console.WriteLine(a);
Console.WriteLine(b);
Console.WriteLine(c);
Func<TIn, TOut> Memoize<TIn, TOut>(Func<TIn, TOut> func)
{
var cache = new Dictionary<TIn, TOut>();
return input =>
cache.TryGetValue(input, out var result)
? result
: cache[input] = func(input);
}
Teraz zobaczmy ten sam przykład tylko mamy kod asynchroniczny, ponieważ korzystam z metody GetStringAsync.
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Threading.Tasks;
var getWebPageAsyncWithCache = Memoize<string, Task<string>>(GetWebPageAsync);
var a = getWebPageAsyncWithCache("https://cezarywalenciuk.pl")
.ContinueWith(p => Console.WriteLine(p.Result.Length));
var b = getWebPageAsyncWithCache("https://cezarywalenciuk.pl")
.ContinueWith(p => Console.WriteLine(p.Result.Length));
var c = getWebPageAsyncWithCache("https://cezarywalenciuk.pl")
.ContinueWith(p => Console.WriteLine(p.Result.Length));
Task<string> GetWebPageAsync(string uri) => new HttpClient().GetStringAsync(uri);
Console.WriteLine(a.Status);
Console.WriteLine(b.Status);
Console.WriteLine(c.Status);
Console.ReadKey();
Func<TIn, TOut> Memoize<TIn, TOut>(Func<TIn, TOut> func)
{
var cache = new Dictionary<TIn, TOut>();
return input =>
{
lock (cache)
return cache.TryGetValue(input, out var result)
? result
: cache[input] = func(input);
};
}
Największą różnica leży w kodzie, w którym byśmy sprawdzali nasz słownik. Załóżmy, że z jakiegoś powodu nie możemy zmienić klasy Dictionary. W takim wypadku na ratunek przychodzi słowo kluczowe "lock"
Nasz słownik żyję dzięki mechanizmowi domknięcia.
Func<TIn, TOut> Memoize<TIn, TOut>(Func<TIn, TOut> func)
{
var cache = new Dictionary<TIn, TOut>();
return input =>
{
lock (cache)
return cache.TryGetValue(input, out var result)
? result
: cache[input] = func(input);
};
}To wszystko, ale jak widzisz warto było wrócić do tematyki Precomputation i Memoization, gdy mówimy o operacjach asynchronicznych.
Warto wtedy albo skorzystać ze słowa kluczowego "lock", albo skorzystać ze słownika ConcurrentDictionary, który jest bezpieczny, gdy korzystamy w wielowątkowości


